最近节日期间最火的除了《哪吒》就是deepseek了,毕竟又让西方各个层面都瑟瑟发抖的产品。DeepSeek凭借其强大的AI能力真的是在全球多个领域展现出强大的影响力。
DeepSeek的应用现在全球下载榜单登顶,流量巨大。国内网都在讨论和使用,朋友圈充斥着各种关于deepseek的新闻,先一起来看看deepseek最近发生了什么:
- 澳大利亚发布禁令:当地时间2025年2月4日,澳大利亚内政部长托尼·伯克签署“强制性指令”,以国家安全为由,禁止在政府系统和设备上使用DeepSeek产品、应用程序和网络服务,要求政府部门和机构尽快向内政部报告,确保DeepSeek不会残留在任何设备上,且禁止重新安装。
- 美国相关法案及举措:美国国会提出《2025年美国人工智能能力与中国脱钩法案》,若通过,任何美国人使用DeepSeek等中国AI模型,个人最高面临20年监禁和100万美元罚款,企业罚款1亿美元并支付3倍赔偿金。美国德克萨斯州已率先禁止政府设备使用DeepSeek,NASA、国防部等联邦机构也紧急封杀相关产品。
下面是各个厂商对deepseek模型的适配情况: - 百度智能云:2月3日,百度智能云千帆平台正式上架DeepSeek – R1和DeepSeek – V3模型,推出超低价格方案,用户可享受限时免费服务。
- 阿里云:2月3日,阿里云PAI Model Gallery支持云上一键部署DeepSeek – V3、DeepSeek – R1,用户可零代码实现从训练到部署再到推理的全过程。
- 华为云:2月1日,华为云与硅基流动团队联合首发并上线基于华为云昇腾云服务的DeepSeek R1/V3推理服务。
- 腾讯云:2月2日,DeepSeek – R1大模型一键部署至腾讯云HAI上,开发者仅需3分钟即可接入调用。2月4日,腾讯云TI平台推出“开发者大礼包”,DeepSeek全系模型一键部署,部分模型限免体验。
- 京东云:2月5日,京东云正式上线DeepSeek – R1和DeepSeek – V3模型,支持公有云在线部署、专混私有化实例部署两种模式。
- 其他平台:360数字安全、云轴科技、天翼云等平台也先后宣布对DeepSeek模型的支持。
- 英伟达:北京时间1月31日,英伟达宣布DeepSeek – R1模型登陆NVIDIA NIM,称DeepSeek – R1是最先进的大语言模型。
- 亚马逊:1月31日,亚马逊宣布DeepSeek – R1模型已可以在Amazon Web Services上使用,其首席执行官安迪·贾西告诉用户“尽管用”。
- 微软:1月31日,微软接入了DeepSeek – R1模型。
大过年的不放假只是为了这波流量吗?先看看这波流量有多香:
根据市场分析公司 Appfigures 数据 (不包括中国第三方应用商店),1 月 26 日,DeepSeek 首次登上苹果 App Store 下载量榜首,并一直保持全球领先地位,Sensor Tower 研究显示,1 月 28 日起,DeepSeek 在美国谷歌 Play Store 也位居榜首。自 1 月 20 日 DeepSeek – R1 模型正式发布后,其 APP 在短短 18 天内,全球下载量突破 1600 万次,成功登顶 140 个国家和地区的下载榜首,这一数字几乎是竞争对手 OpenAI 的 ChatGPT 在同期下载量的两倍。其中印度成为 DeepSeek 最大的用户来源国,自推出以来,印度用户下载量占所有平台下载总量的 15.6%。
从日活数据来看,根据国内 AI 产品榜统计,DeepSeek 应用上线 20 天,日活就突破了 2000 万,并且 DeepSeek 应用 (不包含网站数据) 上线 5 天日活就已超过 ChatGPT 上线同期日活,成为全球增速最快的 AI 应用 ,日活数量的快速增长,充分印证了 DeepSeek 对 C 端用户广泛的吸引力。
一、deepseek是什么?
DeepSeek 是中国开发的大规模人工智能模型,旨在处理和生成类人文本、分析海量数据并协助复杂决策。与 OpenAI 的GPT-4或谷歌的Gemini 一样,DeepSeek 也能准确地理解、解释和生成内容。
此外deepseek还有以下特色能力:
- 强大的推理能力
- 支持长链推理:能够生成数万字的思维链,在处理复杂任务时,可显著提高推理准确性。
- 自我验证与反思:通过强化学习训练,模型能够自主发展包括自我验证、反思等高级认知功能。
- 多语言支持:基于混合专家架构(Mixture of Experts, MoE),可支持多种语言和技术领域,能对不同语言的问题生成相应语言的回答。
- 高效部署与成本效益:运行成本仅为 OpenAI 的 3% 左右,还提供了 API 服务,降低了企业用户的使用门槛。
- 创新训练策略
- 多阶段渐进训练:训练过程分为预备阶段、冷启动微调、纯强化学习、数据合成与筛选、二次微调(SFT)以及后续强化学习优化等几个阶段,避免一次性训练的灾难性遗忘,逐步强化不同能力。
- 混合奖励机制:结合任务结果验证与人类偏好,在强化学习阶段设计了准确性奖励、格式奖励等,还引入了模型基于奖励、语言一致性奖励等,平衡性能与安全性。
- 海量参数与选择性激活
- 海量参数:DeepSeek R1 共有 6710 亿个参数,由多个专家网络组成。
- 选择性激活:每次只使用 6710 亿个参数中的 370 亿个,确保模型只使用任务所需的参数,优化计算效率。
由于受到外部势力的恶意攻击倒是deepseek官方服务不稳定,国内其他厂家的适配版本也不是很稳定,所以在自己电脑部署一个本地离线模型就可以解决很大问题。
本文我们介绍基于ollama的Mac Arm系统详细部署。
一、我们应该部署DeepSeek哪个版本?
根据官方信息DeepSeek R1 可以看到提供多个版本,包括完整版(671B 参数)和蒸馏版(1.5B 到 70B 参数)。完整版性能强大,但需要极高的硬件配置;蒸馏版则更适合普通用户,硬件要求较低
DeepSeek-R1官方地址:https://github.com/deepseek-ai/DeepSeek-R1
- 完整版(671B):需要至少 350GB 显存/内存,适合专业服务器部署
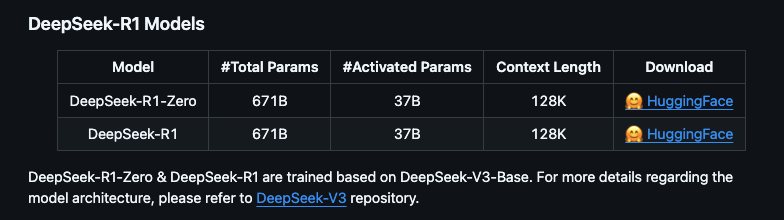
- 蒸馏版:基于开源模型(如 QWEN 和 LLAMA)微调,参数量从 1.5B 到 70B 不等,适合本地硬件部署。
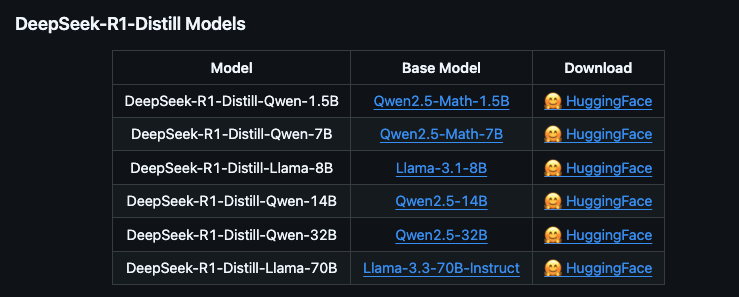
蒸馏版与完整版的区别
| 特性 | 蒸馏版 | 完整版 |
|---|---|---|
| 参数量 | 参数量较少(如 1.5B、7B),性能接近完整版但略有下降。 | 参数量较大(如 32B、70B),性能最强。 |
| 硬件需求 | 显存和内存需求较低,适合低配硬件。 | 显存和内存需求较高,需高端硬件支持。 |
| 适用场景 | 适合轻量级任务和资源有限的设备。 | 适合高精度任务和专业场景。 |
这里我们详细看下蒸馏版模型的特点
| 模型版本 | 参数量 | 特点 |
|---|---|---|
deepseek-r1:1.5b |
1.5B | 轻量级模型,适合低配硬件,性能有限但运行速度快 |
deepseek-r1:7b |
7B | 平衡型模型,适合大多数任务,性能较好且硬件需求适中。 |
deepseek-r1:8b |
8B | 略高于 7B 模型,性能稍强,适合需要更高精度的场景。 |
deepseek-r1:14b |
14B | 高性能模型,适合复杂任务(如数学推理、代码生成),硬件需求较高。 |
deepseek-r1:32b |
32B | 专业级模型,性能强大,适合研究和高精度任务,需高端硬件支持。 |
deepseek-r1:70b |
70B | 顶级模型,性能最强,适合大规模计算和高复杂度任务,需专业级硬件支持。 |
进一步的模型细分还分为量化版
| 模型版本 | 参数量 | 特点 |
|---|---|---|
deepseek-r1:1.5b-qwen-distill-q4_K_M |
1.5B | 轻量级模型,适合低配硬件,性能有限但运行速度快 |
deepseek-r1:7b-qwen-distill-q4_K_M |
7B | 平衡型模型,适合大多数任务,性能较好且硬件需求适中。 |
deepseek-r1:8b-llama-distill-q4_K_M |
8B | 略高于 7B 模型,性能稍强,适合需要更高精度的场景。 |
deepseek-r1:14b-qwen-distill-q4_K_M |
14B | 高性能模型,适合复杂任务(如数学推理、代码生成),硬件需求较高。 |
deepseek-r1:32b-qwen-distill-q4_K_M |
32B | 专业级模型,性能强大,适合研究和高精度任务,需高端硬件支持。 |
deepseek-r1:70b-llama-distill-q4_K_M |
70B | 顶级模型,性能最强,适合大规模计算和高复杂度任务,需专业级硬件支持。 |
蒸馏版与量化版
| 模型类型 | 特点 |
|---|---|
| 蒸馏版 | 基于大模型(如 QWEN 或 LLAMA)微调,参数量减少但性能接近原版,适合低配硬件。 |
| 量化版 | 通过降低模型精度(如 4-bit 量化)减少显存占用,适合资源有限的设备。 |
例如:
deepseek-r1:7b-qwen-distill-q4_K_M:7B 模型的蒸馏+量化版本,显存需求从 5GB 降至 3GB。deepseek-r1:32b-qwen-distill-q4_K_M:32B 模型的蒸馏+量化版本,显存需求从 22GB 降至 16GB
我们正常本地部署使用蒸馏版就可以.
三、Deepseek本地部署教程
Deepseek 本地部署硬件要求
- Windows 配置:
- 最低要求:NVIDIA GTX 1650 4GB 或 AMD RX 5500 4GB,16GB 内存,50GB 存储空间
- 推荐配置:NVIDIA RTX 3060 12GB 或 AMD RX 6700 10GB,32GB 内存,100GB NVMe SSD
- 高性能配置:NVIDIA RTX 3090 24GB 或 AMD RX 7900 XTX 24GB,64GB 内存,200GB NVMe SSD
- Linux 配置:
- 最低要求:NVIDIA GTX 1660 6GB 或 AMD RX 5500 4GB,16GB 内存,50GB 存储空间
- 推荐配置:NVIDIA RTX 3060 12GB 或 AMD RX 6700 10GB,32GB 内存,100GB NVMe SSD
- 高性能配置:NVIDIA A100 40GB 或 AMD MI250X 128GB,128GB 内存,200GB NVMe SSD
- Mac 配置:
- 最低要求:M2 MacBook Air(8GB 内存)
- 推荐配置:M2/M3 MacBook Pro(16GB 内存)
- 高性能配置:M2 Max/Ultra Mac Studio(64GB 内存)
可根据下表配置选择使用自己的模型
可根据下表配置选择使用自己的模型
| 模型名称 | 参数量 | 大小 | VRAM (Approx.) | 推荐 Mac 配置 | 推荐 Windows/Linux 配置 |
|---|---|---|---|---|---|
deepseek-r1:1.5b |
1.5B | 1.1 GB | ~2 GB | M2/M3 MacBook Air (8GB RAM+) | NVIDIA GTX 1650 4GB / AMD RX 5500 4GB (16GB RAM+) |
deepseek-r1:7b |
7B | 4.7 GB | ~5 GB | M2/M3/M4 MacBook Pro (16GB RAM+) | NVIDIA RTX 3060 8GB / AMD RX 6600 8GB (16GB RAM+) |
deepseek-r1:8b |
8B | 4.9 GB | ~6 GB | M2/M3/M4 MacBook Pro (16GB RAM+) | NVIDIA RTX 3060 Ti 8GB / AMD RX 6700 10GB (16GB RAM+) |
deepseek-r1:14b |
14B | 9.0 GB | ~10 GB | M2/M3/M4 Pro MacBook Pro (32GB RAM+) | NVIDIA RTX 3080 10GB / AMD RX 6800 16GB (32GB RAM+) |
deepseek-r1:32b |
32B | 20 GB | ~22 GB | M2 Max/Ultra Mac Studio | NVIDIA RTX 3090 24GB / AMD RX 7900 XTX 24GB (64GB RAM+) |
deepseek-r1:70b |
70B | 43 GB | ~45 GB | M2 Ultra Mac Studio | NVIDIA A100 40GB / AMD MI250X 128GB (128GB RAM+) |
deepseek-r1:1.5b-qwen-distill-q4_K_M |
1.5B | 1.1 GB | ~2 GB | M2/M3 MacBook Air (8GB RAM+) | NVIDIA GTX 1650 4GB / AMD RX 5500 4GB (16GB RAM+) |
deepseek-r1:7b-qwen-distill-q4_K_M |
7B | 4.7 GB | ~5 GB | M2/M3/M4 MacBook Pro (16GB RAM+) | NVIDIA RTX 3060 8GB / AMD RX 6600 8GB (16GB RAM+) |
deepseek-r1:8b-llama-distill-q4_K_M |
8B | 4.9 GB | ~6 GB | M2/M3/M4 MacBook Pro (16GB RAM+) | NVIDIA RTX 3060 Ti 8GB / AMD RX 6700 10GB (16GB RAM+) |
deepseek-r1:14b-qwen-distill-q4_K_M |
14B | 9.0 GB | ~10 GB | M2/M3/M4 Pro MacBook Pro (32GB RAM+) | NVIDIA RTX 3080 10GB / AMD RX 6800 16GB (32GB RAM+) |
deepseek-r1:32b-qwen-distill-q4_K_M |
32B | 20 GB | ~22 GB | M2 Max/Ultra Mac Studio | NVIDIA RTX 3090 24GB / AMD RX 7900 XTX 24GB (64GB RAM+) |
deepseek-r1:70b-llama-distill-q4_K_M |
70B | 43 GB | ~45 GB | M2 Ultra Mac Studio | NVIDIA A100 40GB / AMD MI250X 128GB (128GB RAM+) |
本地安装 DeepSeek R1
1、如果想要在本地运行 DeepSeek 需要用到 Ollama 这个工具,这是一个开源的本地大模型运行工具。
Ollama 作为一款新兴的开源大型语言模型服务工具,在人工智能领域迅速崭露头角,为用户带来了全新的本地化模型部署体验。
它通过提供统一的接口和便捷的操作方式,让用户能够轻松地在自己的设备上部署和使用各种不同的大语言模型,而无需复杂的配置和专业的技术知识。其核心功能在于打破了模型部署的技术壁垒,使得更多人能够享受到本地化大语言模型的优势。
温馨提示:
进入ollama官网的时候会跳转到github,而中国大陆用户访问github会不稳定,就是偶尔上不去,这时候就需要借助梯子进行魔法上网了。
机场俱乐部分享了比较全面的使用机场上外网的教程,具体可以在本站导航栏的“动手做”里面找到和你自己使用设备匹配的教程,照着教程花3分钟时间,你也可以轻松学会上外网。一键连接操作简单,支持外服游戏加速、奈飞视频追剧、网页查资料等;覆盖PC端&移动端;支持安卓系统以及苹果系统;性价比超高,多人使用无压力。
不知道怎么挑选ssr/v2ray机场上外网的也可以参考本站的教程:Top5科学上网梯子IPLC游戏加速器机场推荐
当然,这里面的机场也可以用来当作twitter推特加速器,外服游戏加速器,甚至外贸工作者很多都使用者里面的机场来处理外贸业务。
我们可以访问 https://ollama.com/ 进入 Ollama 官网下载 Ollama ,下载时有三个系统的安装包可选择,这里只需要选择下载我们电脑对应的操作系统版本即可,这里我选择的是 Windows 版本。
2、Ollama 安装包下载完成后直接双击安装即可,安装速度还是比较快的。
Ollama 安装完成后需要打开电脑的 CMD (ctrl+r组合键),也就是命令提示符,或者在电脑下方的搜索框中输入 cmd 即可打开。
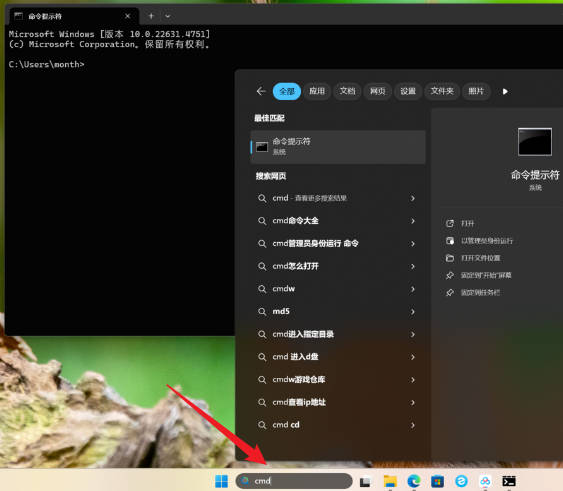
3、打开后在命令提示符窗口中输入 ollama help 并按回车键,这个操作是为了验证这个软件是否安装成功,如果没有报错的话则表示这个软件安装成功。
四、下载部署 Deepseek 模型
1、回到 https://ollama.com/ 网址中,在网页上方搜索框中输入 Deepseek-r1,这个 Deepseek-r1 就是我们需要本地部署的一个模型。
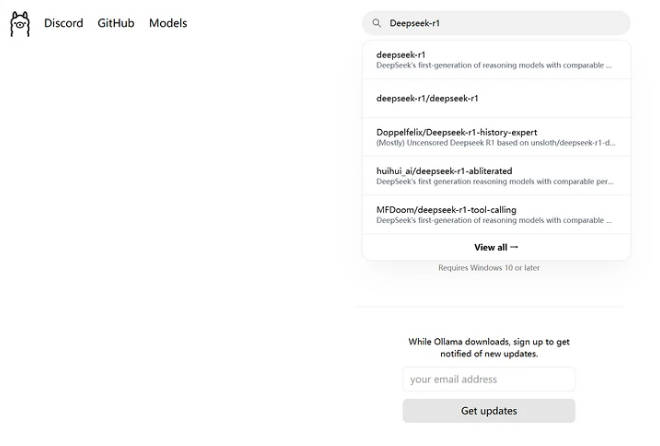
2、点击 Deepseek-r1 后会进入详情界面,里面有多个参数规模可供选择,从 1.5b 到 671b 都有。
需注意的是,这里我们需要根据自己电脑的硬件配置来选择模型大小,下面是一个模型大小配置参考表格,大家可根据自己的电脑配置来自行选择,当然了,部署的本地模型越大,使用的深度求索效果就越好。
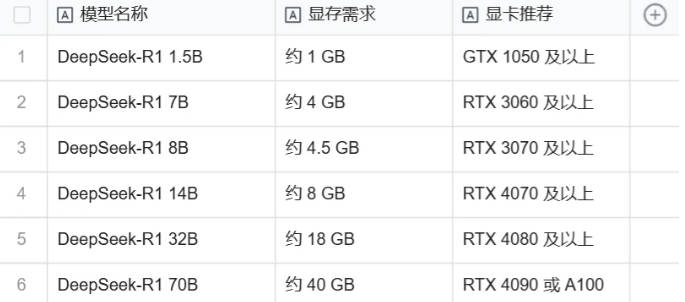
3、像我们普通的电脑安装1.5B,7B就可以使用,然后在【右上角的的代码】复制在命令行中运行。选择好模型规模后,复制右边的一个命令。我这里电脑配置较高,我选的14B.
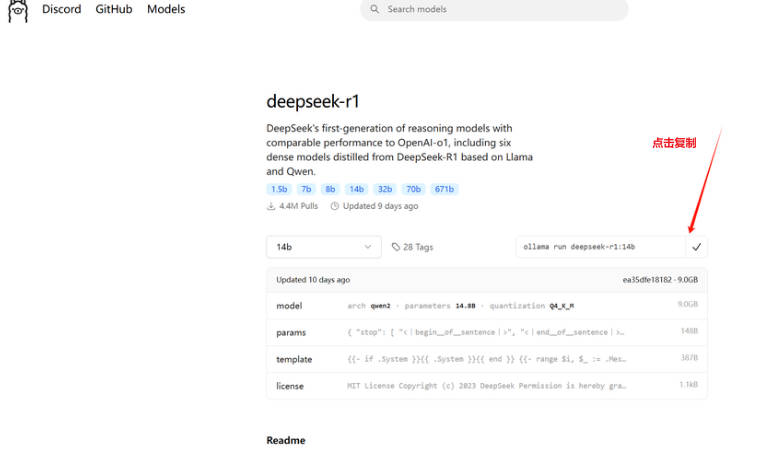
4、命令复制完成后回到命令提示符窗口,将刚刚复制的命令粘贴到命令提示符窗口中并按回车键即可下载模型。
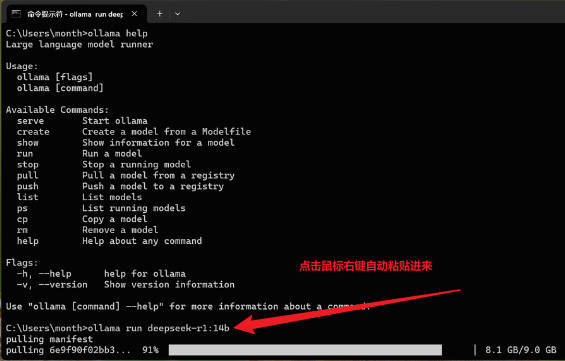
5、模型下载完成后,我们就直接可以在命令提示符面板中使用它了。

以后如果我们需要再次使用 Deepseek 这个模型的话,我们可以直接打开命令提示符窗口,只需要再次在命令符提示窗口中输入上面复制的指令即可。
五、使用Chatbox 部署deepseek-r1
虽然我们可以在本地正常使用 Deepseek 这个模型了,但是这个 AI 工具的面板是非常简陋的,很多人使用不习惯,这时我们就可以通过 Chatbox 这个可视化图文交互界面来使用它。
Chatbox AI 是一款 AI 客户端应用和智能助手,支持众多先进的 AI 模型和 API,可在 Windows、MacOS、Android、iOS、Linux 和网页版上使用。
1、点击进入 Chatbox 官网 https://chatboxai.app/zh ,Chatbox 虽然有本地客户端,但我们也可以直接使用网页版,下载chatbox并安装。
2、进入 Chatbox 网页版本后点击使用自己的 API Key 或本地模型。
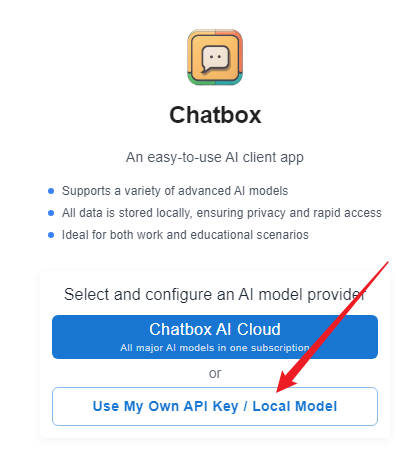
3、点击后会进入模型提供方选择界面,这里选择 Ollama API ,而不是选择下面的deepseek api
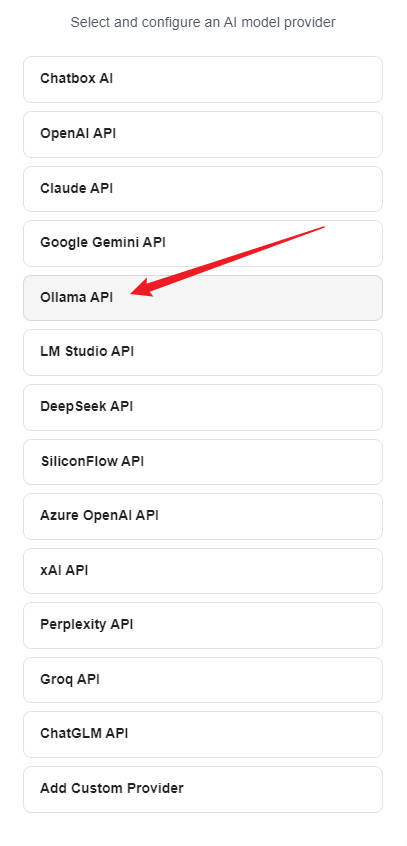
4、这里需要注意的是,为了能够 Ollama 能远程链接,这里我们最好看一下 Chatbox 提供的教程,根据这个教程操作一下。
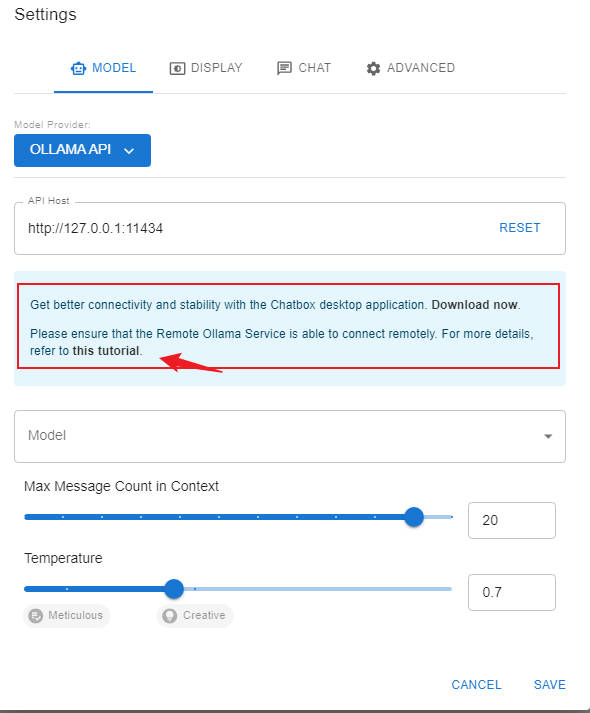
点击save保存。
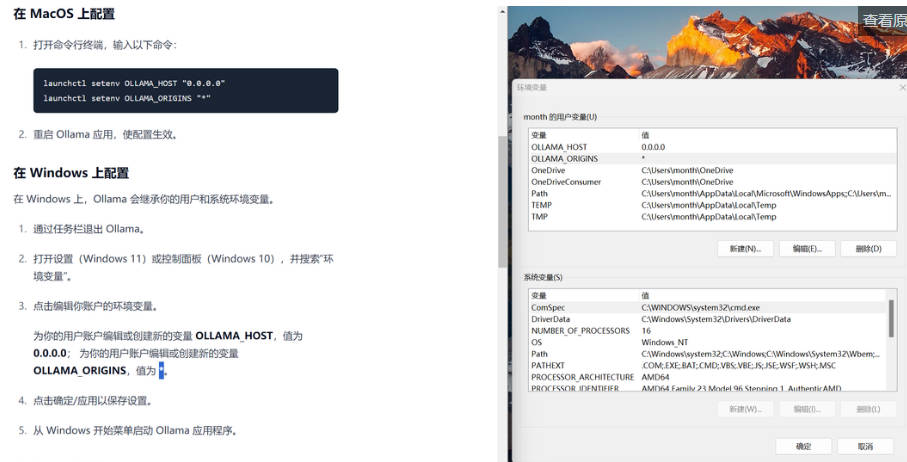
5、这个教程还是非常简单的,如果是 Windows 操作系统则只需要配置一下环境变量即可,配置完环境变量后需重启一下 Ollama 程序。
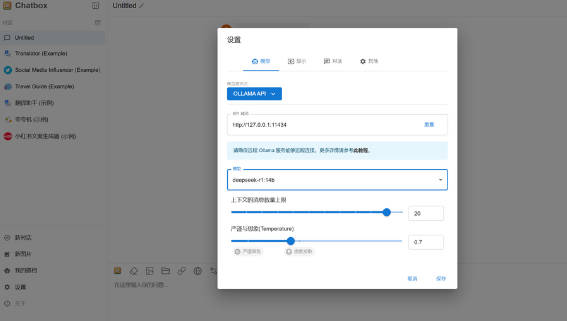
6、重启 Ollama 程序后,我们需要将 Chatbox 设置界面关闭并重新打开,重新打开 Chatbox 设置界面后即可选择 Deepseek 模型了,选择后 Deepseek 模型后点击保存即可。
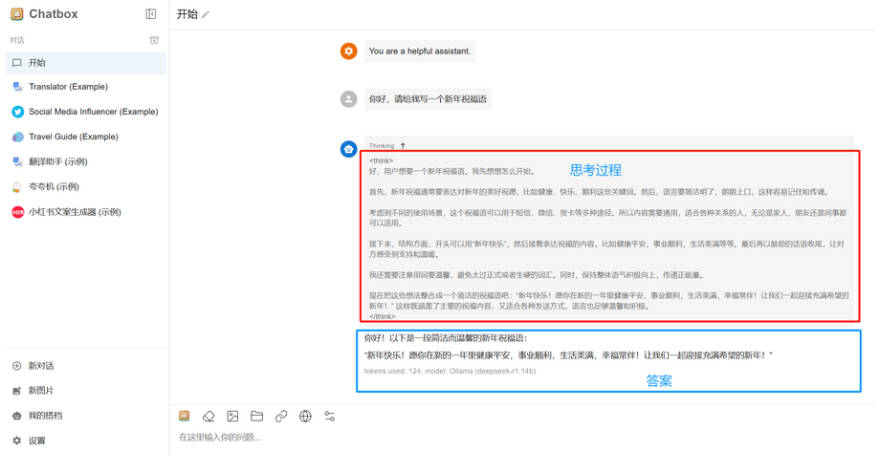
7、接下来只需要在 Chatbox 中新建对话即可使用 Deepseek 模型了,以下图为例,上方是它的思考过程,下方是它给出的答案。
8、Chatbox 可视化图文交互界面还有一个特点就是可以创建专属智能体,只需点击我的搭档即可创建,此功能是 Deepseek 官方暂时还没有的功能。